(2)AI는 왜 자신 있게 틀릴까?
뉴스 원문 정보
원문 : https://milgyonews.net/news/detail.php?wr_id=40240작성 : 밀교신문

최근 기업이나 연구소에서 AI에게 수백 쪽 분량의 계약서나 산업 보고서를 요약하게 했을 때 흔히 벌어지는 일이 있다. AI는 문서 A에 있는 '긍정적 시장 전망'과 문서 B에 있는 전혀 다른 기업의 ‘파산 위험’을 교묘하게 뒤섞어 버린다. 그러고는 원문 어디에도 없는 ‘A 기업의 파산 위기설’을 마치 핵심 요약인 것처럼 기정사실화 해 보고서에 적어 넣는다. 과거처럼 대놓고 황당한 헛소리를 하지는 않지만, 전문가조차 원문을 일일이 대조하지 않으면 속아 넘어갈 만큼 정교하고 그럴듯한 거짓을 만들어내는 것이다.
이 현상을 ‘환각(Hallucination)’이라고 부른다. 존재하지 않는 것을 보는 듯이, AI가 실제로 없는 정보를 있는 것처럼 생성해 낸다는 의미다. 촘촘해진 안전장치 덕분에 기초적인 오류는 눈에 띄게 줄었지만, 환각의 본질은 여전히 해결되지 않은 채 남아있다.
1.세 가지 구조적 한계
AI가 자신 있게 틀리는 이유는 크게 세 가지 구조적 한계에서 비롯된다.
데이터의 빈칸-AI가 바라보는 세계는 학습된 과거의 정보에 갇혀 있다. 여기에는 여러 겹의 빈칸이 존재한다.
시간의 빈칸-AI의 학습은 특정 시점에서 멈춘다. 어제 발표된 뉴스나 올해 출간된 책은 학습 데이터에 포함되어 있지 않다. “2024년 노벨 문학상 수상자는?”라는 질문에 AI는 모른다고 하지 않는다. 대신 기존 패턴을 조합해 그럴듯한 이름을 만들어낸다. 그 사람이 실존하는지 여부는 AI의 고려 대상이 아니다.
공간의 빈칸-학습 데이터는 영미권 중심이어서 특정 지역의 정보는 빈약하다. “을지로 점심 맛집 추천해 줘”라는 질문에 AI가 답을 내놓더라도 그 식당이 실제로 존재하는지 혹은 영업 중인지는 확인되지 않는 경우가 많다.
언어의 빈칸-한국어 데이터는 영어에 비해 상대적으로 적고, 소수 언어는 더욱 희소하다. 같은 질문이라도 영어로 물었을 때와 한국어로 물었을 때 답변의 품질이 달라지는 이유다.
데이터의 편향-더 심각한 문제는 데이터가 가진 편향까지 그대로 학습한다는 점이다.
AI는 학습 데이터에서 더 많이 등장한 패턴을 ‘정상’으로 인식한다. 예를 들어 “간호사”를 이미지 생성 AI에 입력하면 여성이 주로 등장하고, “CEO”를 입력하면 중년 남성이 주로 등장한다. AI는 이 패턴을 그대로 재생산하기 때문에 데이터가 부족하거나 편향된 영역에서는 왜곡되고 차별적인 답변이 나올 수밖에 없다. 무지가 공백으로 남지 않고 적극적인 추측과 편견으로 둔갑하는 것이다.
기억의 물리적 한계-아무리 방대한 지식을 학습했어도, 사용자와 대화할 때 한 번에 펼쳐놓을 수 있는 정보의 양은 한정되어 있다. 이것을 ‘콘텍스트 윈도우’라고 부른다. 비유하자면 AI는 수천 권의 책을 외웠지만, 대화할 때 책상 위에 펼쳐놓을 수 있는 페이지 수는 정해져 있는 셈이다.
대화가 길어지고 문서가 두꺼워질수록 앞서 설정한 중요한 전제들은 책상 밖으로 밀려나 잊혀진다. 긴 회의록을 분석하다가 초반에 언급된 핵심 결정 사항을 잊어버리거나, 소설 원고 검토하다가 1장에 등장한 인물의 설정과 모순되는 내용을 5장에서 쓰는 식이다. AI가 일부러 무시한 것이 아니라 그 정보가 더 이상 참조 범위 안에 남아 있지 않기 때문이다.
2. 보완책의 등장, 그러나 한계
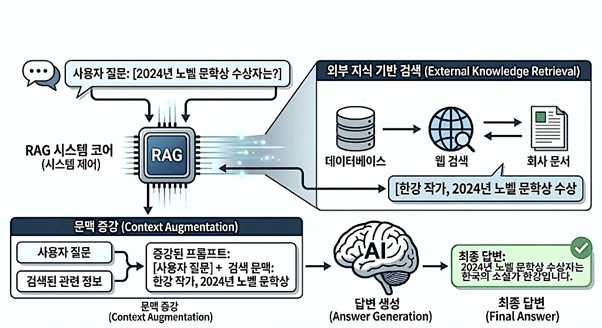
AI 개발사들도 이 약점들을 잘 인지하고 있다. 최근에는 ‘RAG(검색 증강 생성)’라는 방식이 널리 도입되고 있다. AI가 답변을 생성하기 전에 외부 데이터베이스를 실시간으로 검색해서 관련 정보를 가져온 뒤, 그것을 바탕으로 답변을 만드는 방식이다.
이 기술의 활용 범위는 생각보다 넓다. 기업에서는 사내 문서, 계약서, 회의록을 연결해서 “지난 분기 마케팅 예산 집행 내역이 어떻게 됐지?”라고 물으면 AI가 해당 문서를 찾아 요약해 준다. 법률 분야에서는 판례 데이터베이스를 연결해 관련 사례를 검색하고, 의료 분야에서는 최신 논문과 임상 가이드라인을 참조해 진단을 보조한다. 개인도 마찬가지다. 자신이 작성한 노트, 일기, 업무 기록을 AI에 연결하면 “내가 작년에 읽은 책 중에서 리더십에 관한 건 뭐가 있었지?”라고 물을 수 있게 된다. 학습 데이터에 없는 나만의 정보를 AI가 참조할 수 있게 되는 것이다.
콘텍스트 윈도우도 빠르게 확장되고 있다. 초기 모델이 몇천 자 정도만 처리할 수 있었다면, 최신 모델은 수십만 자, 책 한 권 분량을 한 번에 다룰 수 있게 됐다.
그러나 이 모든 보완책에도 근본적인 한계가 여전히 존재한다. RAG가 가져온 정보 자체가 틀렸거나 오래됐더라도, AI는 그것을 검증 없이 그대로 사용한다. 콘텍스트 윈도우가 아무리 넓어져도 무한하지는 않다. 결국 이 모든 기술은 텍스트를 통계적으로 이어 붙이는 본질 위에 덧댄 보조 장치일 뿐, AI가 진실을 스스로 판별하거나 사실과 허구를 구분하는 능력을 갖추게 된 것은 아니다.
3. 한계를 알았으니, 이제 활용할 차례다
AI를 제대로 다루려면 이 도구의 빛과 그림자를 구분해야 한다. 널리 알려진 보편적 지식, 문체의 모방, 전형적인 요약 작업에서는 AI를 신뢰해도 좋다. 반면 최신 정보, 지역 정보, 정확한 출처, 희귀한 지식처럼 데이터가 부족한 영역에서는 반드시 별도의 확인이 필요하다. 중요한 것은 이 구분을 명확히 인식하는 것이다.
AI는 이러한 한계 안에서도 이미 놀라운 성과를 내고 있다. 의사의 진단을 보조하고, 수천 줄의 코드를 작성하고, 몇 시간이 걸리던 번역을 몇 초 만에 끝낸다.
다음 화부터는 AI가 실제로 우리의 일과 삶을 어떻게 바꾸고 있는지, 그리고 우리는 이 도구를 어떻게 일상에 들여놓을 수 있는지 구체적인 사례들을 살펴볼 것이다.
김민지/데이터엔지니어